《All-in-one : Multi-task Learning for Rumour Verification》笔记
Rumour Verification
Introduction
社交媒体作为关注事件和突发新闻的平台越来越受用户欢迎。然而,并不是所有在社交媒体上传播的信息都是准确的,不准确的信息会对社会造成严重的危害。科学界对开发验证社交媒体信息的工具越来越感兴趣,Facebook也投入了大量的努力来减轻错误信息造成的问题。
谣言分辨过程分为四个子任务(如图1):
- 谣言检测,确定一个声明是否值得验证;
- 跟踪谣言,在谣言发生时收集消息来源和观点;
- 立场分类,确定消息来源或用户对谣言真实性的态度;
- 谣言验证,作为预测谣言真实性的最终步骤。
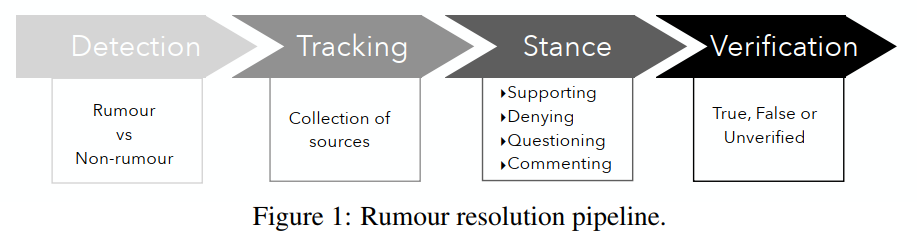
这些步骤可以在谣言生命周期的不同时间执行。理想情况下,谣言可以被认定为真或假。然而,当没有足够的证据来确定它们的真实性时,它们也可能仍然是未经核实的。
谣言分辨过程可以表示为一个多任务问题,其中真实性分类任务是主要任务,其余任务是辅助任务,可以利用这些任务来提高真实性分类器的性能。多任务学习可以帮助密切相关任务的共享表征的学习,即两个互补的任务可以相互给予”提示“。
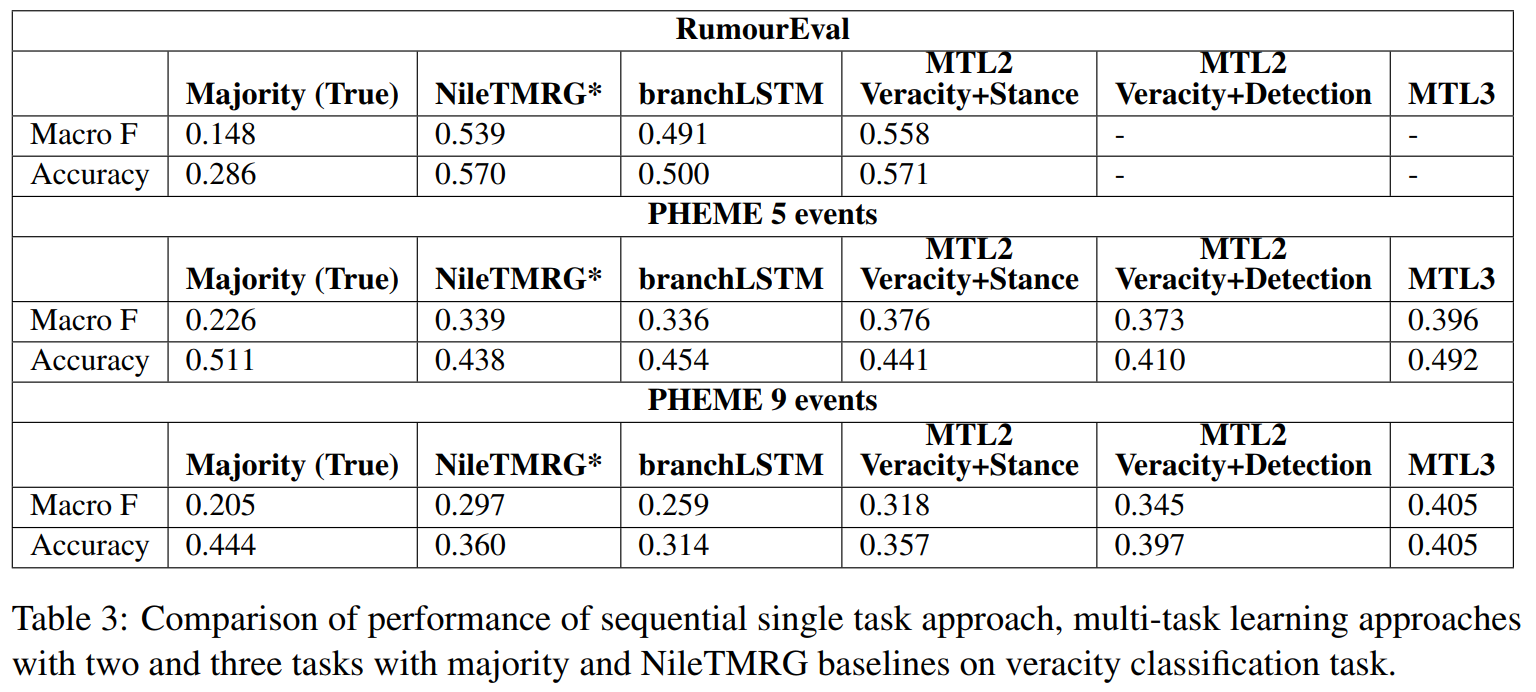
结果利用这三个子任务的多任务学习场景(其中真实性分类是主要任务,立场分类和谣言检测为辅助任务),比单任务的学习与现在最新的系统都有实质性改进。
Related work
Rumour classification system
- (Zubiaga等人,2018a)将谣言检测定义为区分谣言(未经验证的信息)和非谣言(所有其他传播的信息)的任务。谣言检测后,则将被分类为谣言的信息输入到系统的立场分类和验证组件中,最终确定谣言的真实性。
- Stance classification:确定与谣言相关的其他帖子是持支持、否认或是质疑态度,还是只是评论。用户对谣言所表达的立场可以表明谣言的真实性,有研究表明,容易引发否认和质疑的谣言更有可能被证明是错误。之前基于立场分类方面的工作探索了序列分类器的使用,已经证明序列分类器实质上优于标准的,非序列分类器。
- Rumour detection:谣言检测方面的工作更为稀缺。最早的方法之一是由Zhao等人(2015)提出的基于规则的方法,从而确定相关信息是谣言。Zubiaga等人(2017)提出了一种连续的方法来利用事件中早期帖子的上下文。序列方法在召回率方面取得了显著的改进,这是基于规则的方法所缺乏的。
- Rumour verification:谣言验证的常见方法包括从揭露谣言的网站(如snopes.com、emergent.com、politifact.com)收集已解决谣言的语料。Wang(2017)基于politifact.com的声明创建了一个数据集,并根据真实程度进行了标注,提出了一种混合卷积神经网络,将元数据与文本集成在一起。Twitter是一个研究谣言的流行平台,而谣言的种子和注释通常仍然来自辟谣网站。Giasemidis等人(2016)从Twitter收集了72个谣言数据集,这项工作测量了在不同的时间窗下一声明的可信度。
- Sequence classification:考虑谣言检测与谣言验证的工作强调了在处理谣言时采取时序敏感方法的重要性,因此实验中使用基于LSTM的架构。
Multi-task learning
- 多任务学习是指用一个共享的表示形式对几个相关的任务进行联合学习。论文中使用了最常见的多任务学习方法,即hard parameter sharing,这意味着不同的任务使用相同的隐藏层。多任务学习通过使用其他数据集的相关任务和正则化,有效地增加了训练集的规模,而该模型必须学习多个任务的共享表示,减小了在其中某一任务过拟合的风险。在多任务学习中,辅助任务可以用来指导主任务学习由于任务和特征之间的复杂关系而忽略或无法识别的特征。例如,当潜在的有帮助的特性不是作为主要任务使用,而是成为辅助任务中的标签时,多任务学习是特别有用的。在实验中,立场分类可以作真实性分类系统的一种特征,其关系如之前所示。
Data
- 使用的谣言数据集为PHEME和RumourEval,其中包含不同级别的谣言检测、立场识别和谣言验证。
RumourEval
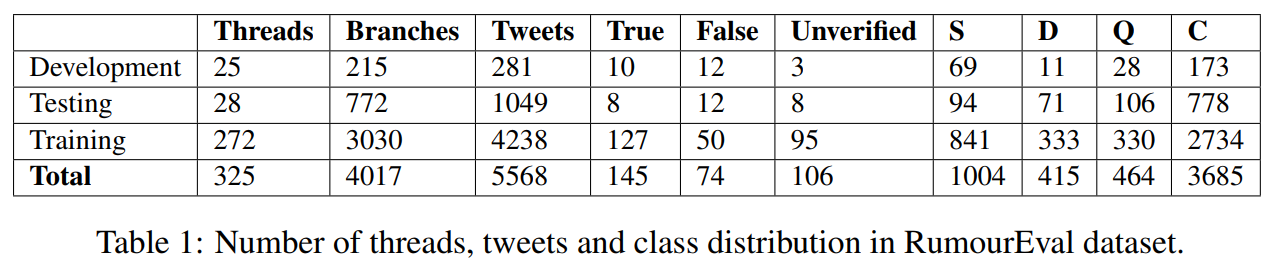
RumourEval是作为the SemEval-2017 Task 8 competition的一部分数据集。它包含325条讨论谣言的推特帖子,RumourEval数据集中的所有对话都是谣言,因此该数据集只涵盖谣言立场和准确性分类的任务。它分为训练、测试和验证集。测试集包含与训练和验证集相同的事件有关的各种谣言,此外还有两个谣言:关于玛丽娜·乔伊斯和希拉里·克林顿的健康状况。
表1显示了RumourEval数据集中每组对话线程、分支和tweet的数量,以及这两个任务的标签分布。在立场分类任务中,质疑Q和否认D较少。对于谣言验证任务,训练集包含的真实例比假实例或未验证实例多,而开发和测试集则更加平衡。
PHEME
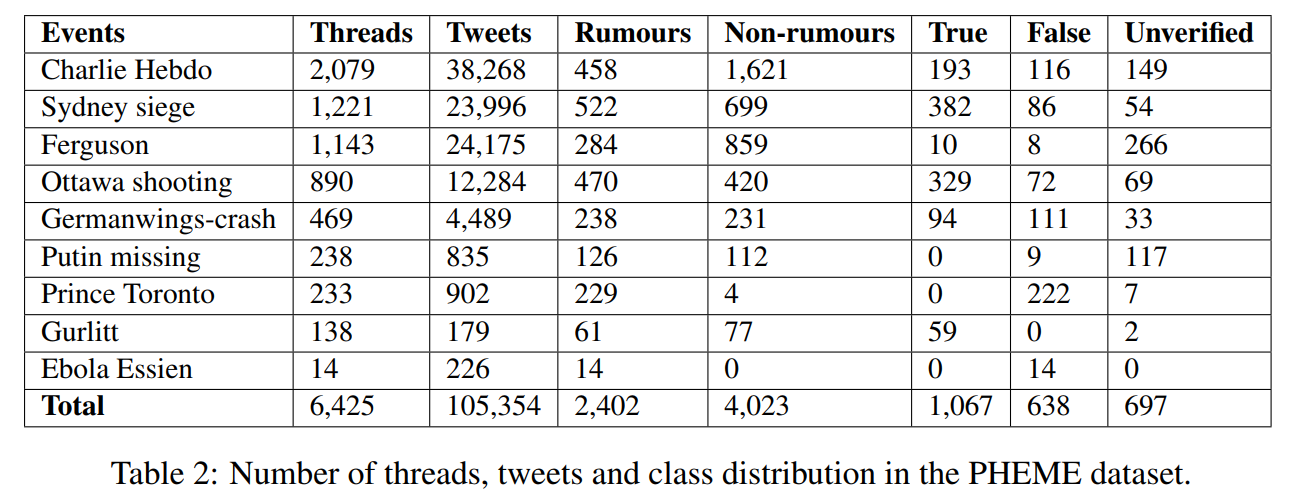
该数据集包含3个级别的注释。首先,每个线程被注释为谣言或非谣言;第二,谣言会被贴上真假或未经证实的标签。第三,通过众包??对一个子集(RumourEval中使用的线程)进行注解,用于推文层面的立场分类。
表2为数据集中每个事件的大小以及谣言检测和验证任务的标签分布。 事件的大小差别很大,并且具有不同的标签比例。总的来说,PHEME数据集包含的谣言比非谣言少,而谣言的大多数是真实的。
Models
Sequential approach
- 遵循Zubiaga等人描述的branchLSTM方法,将对话分解成线性分支,并将它们用作训练实例作为模型输入。该模型由一个LSTM层、几个密集的ReLU层和一个预测分类概率的softmax层组成。由于立场分类任务在一篇推特级别注释,使用每个时间戳LSTM的输出。而对于谣言检测和验证任务,只使用最后一次输出。对于每线程的预测结果,我们对每个分支进行多数投票,利用分类交叉熵损失对模型进行训练。
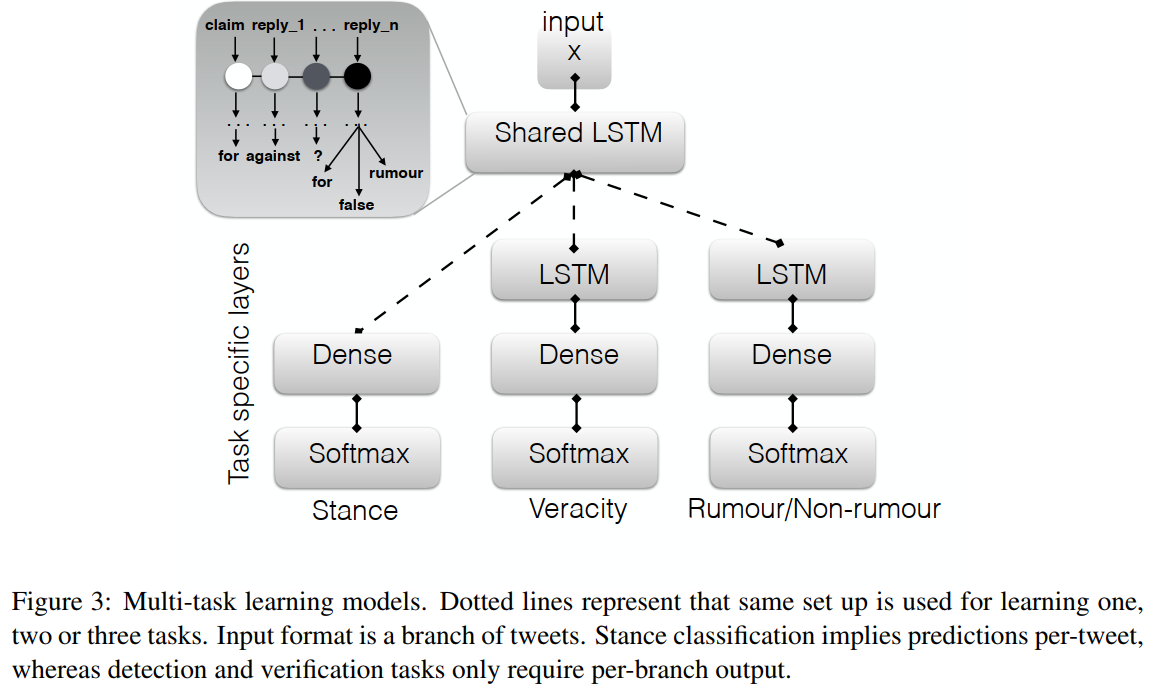
Multi-task learning approach
使用方法如图3。它的基础是一种顺序方法,由共享的LSTM层(硬参数共享)表示,随后是一些特定于任务的层。可能的任务组合在图3中以虚线的形式显示,根据组合的不同,它们可以出现也可以不出现。我们在三种设置下进行实验:立场与谣言验证,谣言检测与谣言验证,以及一起学习所有三个任务。在多任务模型中,成本函数是每个任务损失的总和。三个任务的数据集大小不相等,因此,当训练实例缺少其中一个任务的标签时,它的预测不会给损失函数增加任何东西,就像它被正确地预测了一样。
Baselines
- 采用多数投票法,在谣言验证任务中,由于类别不平衡,因此具有较强的基线,从而获得了较高的准确率。
- NileTMRG是SemEval-2017任务8中的最佳准确性分类系统。NileTMRG模型基于线性的支持向量机(SVM),使用单词袋并结合选定的特征:URL的存在性、hashtag的存在以及支持、否认和查询推文的比例表示推文。实验在NileTMRG模型的基础上做了我们自己的NileTMRG*实现。这个模型需要数据集中每个tweet的立场标签,但是这些标签对于PHEME是不可用的,因此使用了Kochkina的立场分类模型实现,而最终NileTMRG*获得了更好的效果。
- NileTMRG模型显示了流水线任务按顺序执行的场景,上一个步骤(立场分类)的结果作为下一个步骤(谣言验证)的输入,证明了立场分类是谣言验证的有效指标。
Features
- 我们对数据集中的tweet进行以下预处理:删除非字母字符,将所有单词转换为小写,使用NLTK进行词性分类。对推文文本进行预处理后,我们对一条推文中的每个单词提取谷歌新闻数据集上预先训练好的word2vec词嵌入,并取其平均值,得到一条推文表示。由于tweet的长度较短,这种表示方式在tweet上表现得很好。
Experiment setup
使用the Tree of Parzen Estimators (TPE)算法来搜索参数空间,相关超参数设置见原论文。
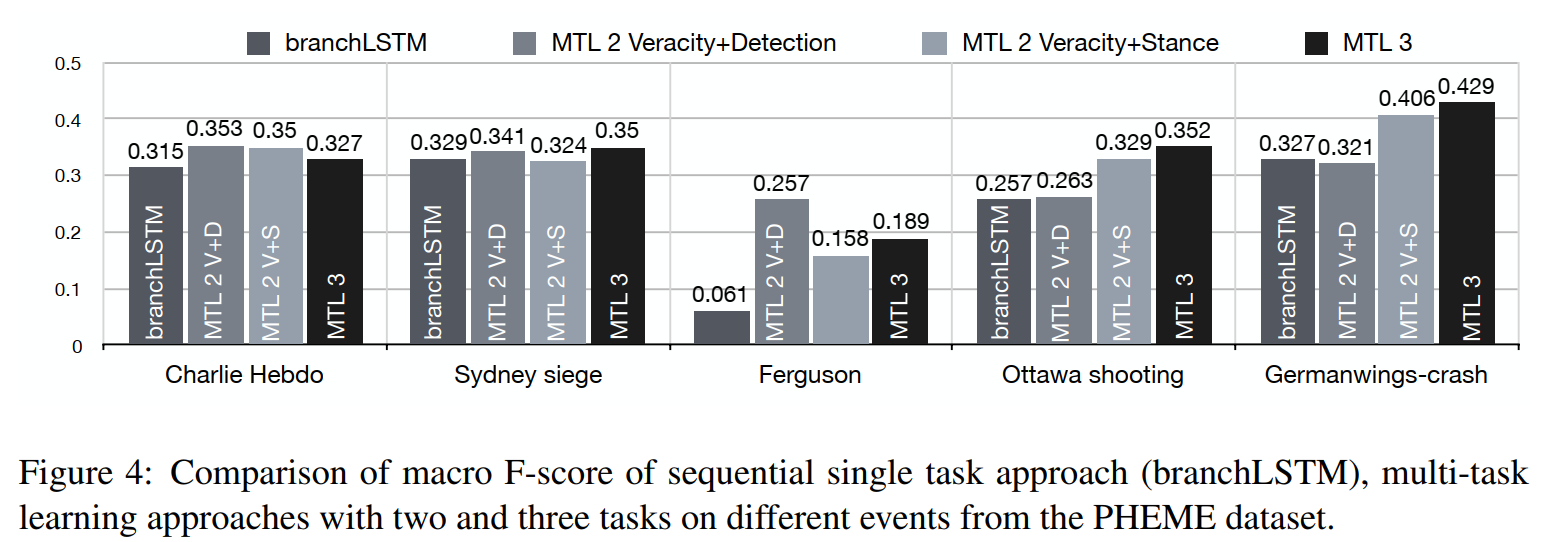
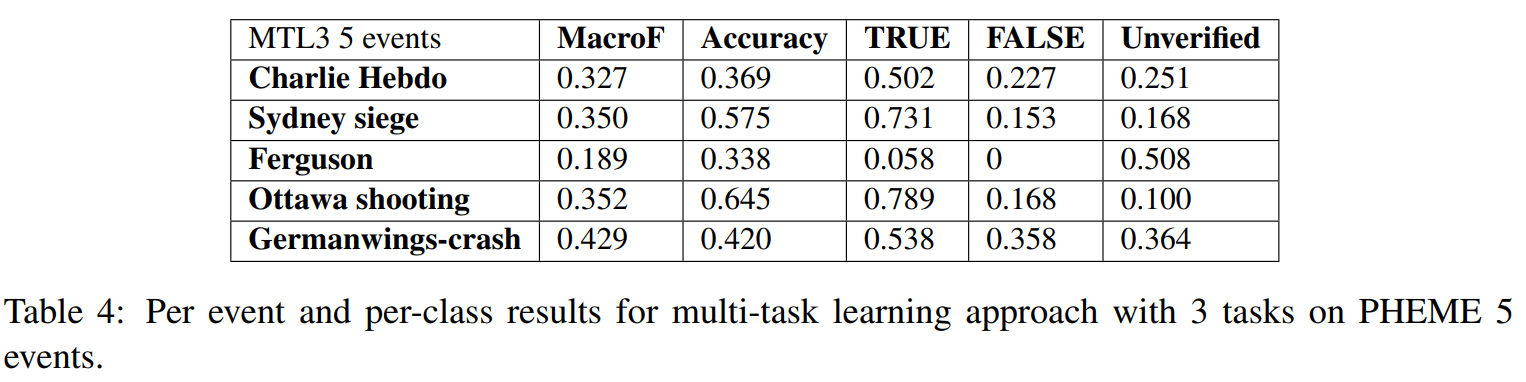
最终结果如下图
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!