《Detecting Rumors from Microblogs with Recurrent Neural Networks》笔记
Detecting Rumors with Recurrent Neural Networks
Introduction
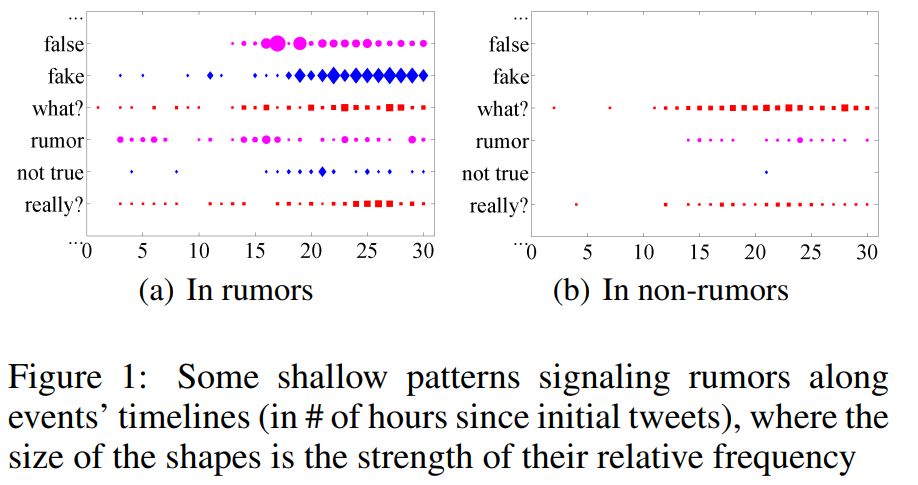
社会心理学文献将谣言定义为一个真实性未经证实或故意造假的故事或陈述。现有的谣言检测模型使用了学习算法结合了从帖子的内容、用户特征和扩散模式中得到的特征,或者简单地利用正则表达式来发现推文中的谣言。特性工程是至关重要的,但它是非常细致、有偏见和需要人工的。例如,图1中的两个时间序列图描述了中典型谣言信号的浅层模式。虽然它们可以显示谣言事件和非谣言事件的时间特征,但对于特征工程来说,这两种情况之间的差异既不明显也不强烈。
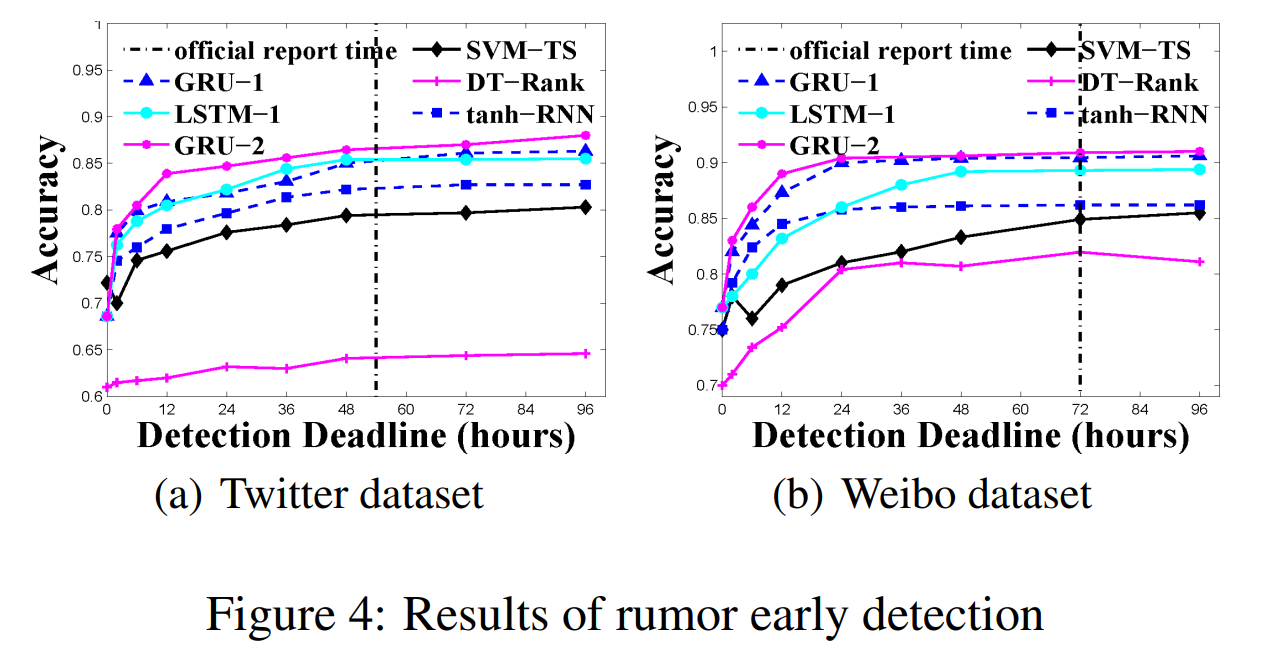
- RNN适合于谣言检测,这是因为RNN中单元之间的连接循环形成了网络的内部状态,这能够捕捉到谣言扩散的动态特征。利用RNN,我们将事件的社会语境信息建模为一个变长时间序列。我们假设人们在听到谣言时会转发谣言或对其发表评论,从而产生连续不断的帖子。方法在监督下学习谣言帖子的时间和文本特征。在两个真实的微博数据集上进行的大量实验表明,基于RNN的方法具有出色的性能。该模型也被证明对谣言的早期检测是有效的,在谣言最初传播几小时后就可以获得足够的准确性。
- 据我们所知,这是首次使用深度学习模型来检测微博上的谣言。基于rnn的模型实现了显著的改进,超过了最先进的学习算法与依赖手工制作的特征。该模型具有更强的可扩展性,通过复杂的循环单元和额外的隐藏层,可以比现有的方法更准确地检测谣言。
- 基于RNN的模型与现有的检测相比(如在线谣言揭穿服务)相比允许早期检测,更有效。
- 我们为任务构建了两个带有ground truth标签的微博数据集,总共包含超过5000个声明,扩展到500万条相关微博帖子。我们将这个庞大的谣言数据集完全公开,以便用于研究目的。
Related Work
- 之前的研究多用手工制作的特征,使用了超过文本之外的内容。
- Zhao等人[2015]利用“not true”、“unconfirmed”或“debunk”等提示词,对质疑和否认推文进行早期的谣言检测。
RNN: Recurrent Neural Network
RNN: Recurrent Neural Network
Long Short-Term Memory (LSTM)
Gated Recurrent Unit (GRU)
RNN-based Rumor Detection
- 首先,我们引入一种方法,将输入的微博帖子转换为连续的变长时间序列,然后用不同类型隐藏层单元和层树进行分类。
- 我们定义一组给定的事件为$E = \{E_i\}$,其中每个事件$E_i = {(m_{i,j}, t_{i,j})}$由时间戳$t_{i,j}$上的所有相关帖子$m_{i,j}$组成,任务是将每个事件分类为谣言或非谣言。
Variable-length Time Series
由于一个热门事件中可能会有成千上万的帖子,而最终只有一个分类的输出单元。反向传播通过大量的时间序列,会导致梯度消失或爆炸。因此将帖子按一定时间间隔处理作为序列中的单个单元,再使用RNN建模。最初,我们将整个时间线平均划分为$N$个间隔($N$是参考长度)。系统尝试通过删除集合$U_0$中的空间隔来发现非空间隔的集合$U’$(即,$U’$中的每个间隔至少具有一条推特)。这些非空间隔中总时间跨度最长的被选入集合$\bar U$。 如果$\bar U$中的间隔数小于$N$,并且间隔数大于上一轮的间隔数,我们将间隔减半并继续进行分区; 否则,它返回由$\bar U$给定的发现的连续间隔。算法如下

Structures of Models
根据上节构建的时间序列,RNN的循环单元自然地拟合时间间隔。在每个区间内,我们使用区间内词语的$tf\ast idf$值作为输入。我们根据$tf\ast idf$值保留最前面的$K$项来对词进行删减,因此输入维数为$K$。RNN的结构如图2所示。注意,输出单元与最后的时间步骤相关联,它使用softmax来实现这两个类的概率输出。
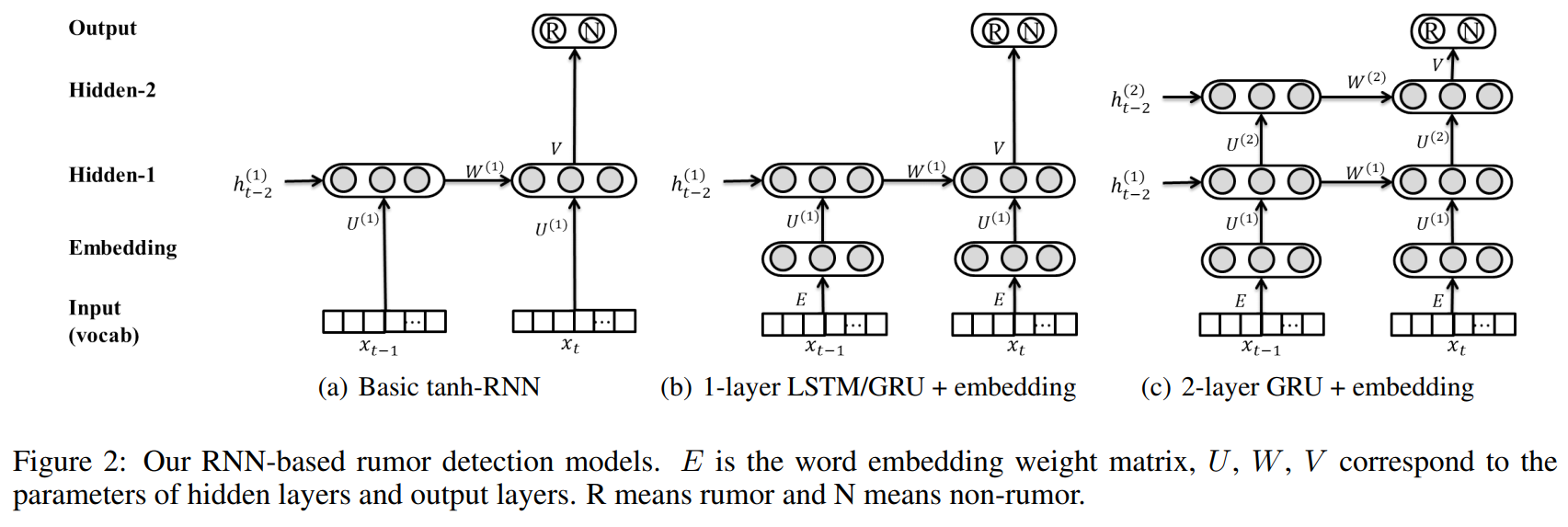
tanh-RNN:最基本的结构,其中隐藏的单元不是门控的,以有限的方式捕获跨时间间隔的上下文。设$g_c$为ground-truth,其中$c$表示类标签事件的二维多项式分布。对于每个训练实例(即每个事件),我们的目标是最小化预测概率分布与真实值之间的平方误差:
其中$g_c$和$p_c$分别是目标分布和预测分布,$\theta_i$表示待估计的模型参数,使用L2正则化惩罚。
Single-layer LSTM and GRU :长距离依赖关系对于捕获事件生命周期中的谣言形式和隐藏特征非常重要。门控单元不仅保留了当前时间步长的内容,而且还注入了前一步的学习到信息。然而,由于门控单元的存在,参数的规模明显增大。例如,GRUs由于引入了复位门和更新门,使得原有的参数空间增加了三倍。为了降低复杂度,我们在输入层和隐藏层之间添加了一个嵌入层(固定长度为100),使得参数的规模变得更小。不使用预先训练的基于外部集合的向量,而是使用我们的模型自己学习嵌入向量$E$。
Multi-layer GRU:通过添加第二个GRU层来捕捉不同时间步长之间更高层次的特征。考虑到LSTMs更复杂的参数集,我们只将GRU扩展为多个层。
Model Training:通过利用损失的反向传播对所有参数的导数来训练所有RNN模型,使用AdaGrad算法进行参数更新。词汇大小$K$设为5000,嵌入向量大小设为100,隐藏单元大小设为100,学习率设为0.5。
Experiments and Results
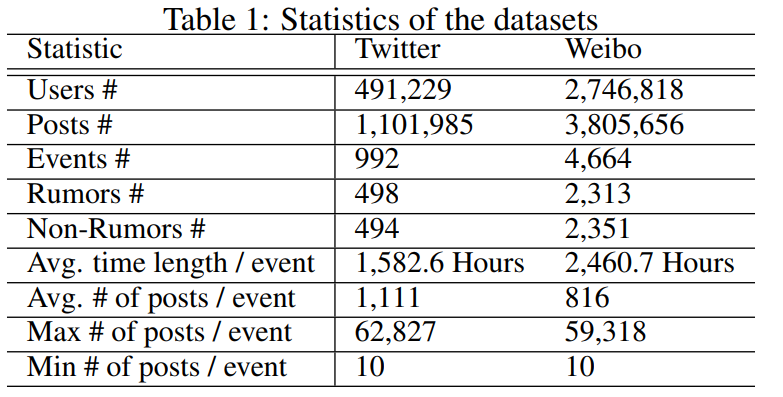
使用的数据集信息如下
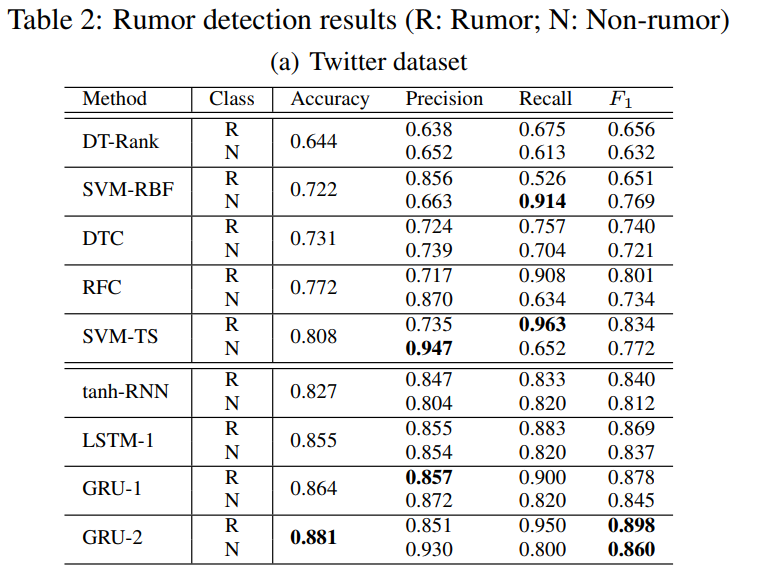
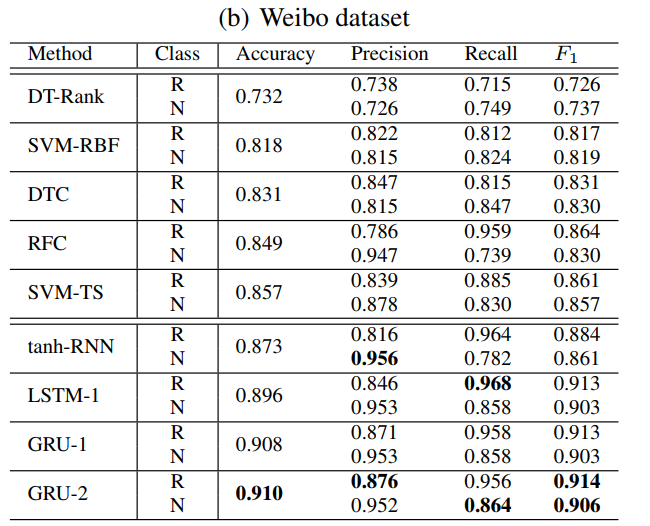
实验结果
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!