《A Convolutional Approach for Misinformation Identification》笔记
A Convolutional Approach for Misinformation Identification
Introduction
GRU-2的缺点:在错误信息输入序列有限的情况下,GRU-2不具备实际早期检测任务的条件。有限的输入序列可能不够长,不足以体现动态时序信号,因此GRU-2在某些情况下不会捕捉到动态时间信号特征;训练后的RNN模型具有一个恒定的递归转移矩阵,并导致序列信号在每两个连续输入之间的传播方式相同,这对于动态和复杂的情况是不够的;GRU-2模型偏向于输入序列的最新元素但关键特征不一定出现在输入序列的后部。
CNN的卷积架构和$k$-max pooling操作可以灵活地提取分散在一个输入序列中的关键特征。论文提出了一种用于错误信息识别和早期检测任务的Convolutional Approach for Misinformation Identification (CAMI)模型。首先,我们研究了所采用的数据集中的数据分布(详见第3节),观察错误信息和真实信息的长尾分布。在此基础上,我们提出了适当的方法将每个事件划分为几个阶段,将所有事件分成若干组微博,通过段落向量学习每组的表示。因此,CAMI的输入序列是由事件分成的组。CAMI不仅能自动从输入实例中提取局部-全局的重要特征,而且还能灵活地提取分散在一个输入序列中的关键特征。CAMI模型的可视化实验中获得了一些观察结果,该模型有助于更好地理解人类在网络空间中的行为,并更准确地塑造现实社会媒体场景。
主要贡献:
我们使用无监督的段落向量方法学习输入微博帖子的表示,使用有监督的CNN方法自动获取虚假信息和真实信息的关键特征。
我们将所提出的模型所捕获的信息可视化,这将帮助我们理解社交媒体上的信息所具有的内在属性。
在两个真实世界的数据集上进行的实验表明CAMI在错误信息识别方面明显优于最先进的方法。
Related Work
之前的研究多用手工制作的特征,使用了超过文本之外的内容。
此外,其他一些作品提取了更有效的手工制作特征,包括冲突观点[Jin等人,2016],时间属性[Kwon等人,2013;Ma等人,2015],用户反馈[Giudice, 2010;Rieh et al],并发出包含怀疑的推文[赵等人,2015]。上述基于特征工程的方法都未能覆盖动态复杂社交媒体场景中的潜在特征,未能形成重要特征之间更深层的交互。为了克服这些缺陷,基于RNN的模型试图捕捉错误信息扩散过程中的动态时间信号,并逐步学习事件的时间和文本表示,而不依赖任何手工制作的特征[Ma等人,2016]。
CNN由堆叠的卷积层和池化层组成,这些结构有助于建模重要的语义特征,并在各自的领域取得了很大的改进。例如,CNN已成功应用于语音识别、句子语义分析、点击率预测]、图像语义分割和强化学习任务]。CNN通常采用随机梯度下降训练,用反向传播计算梯度。
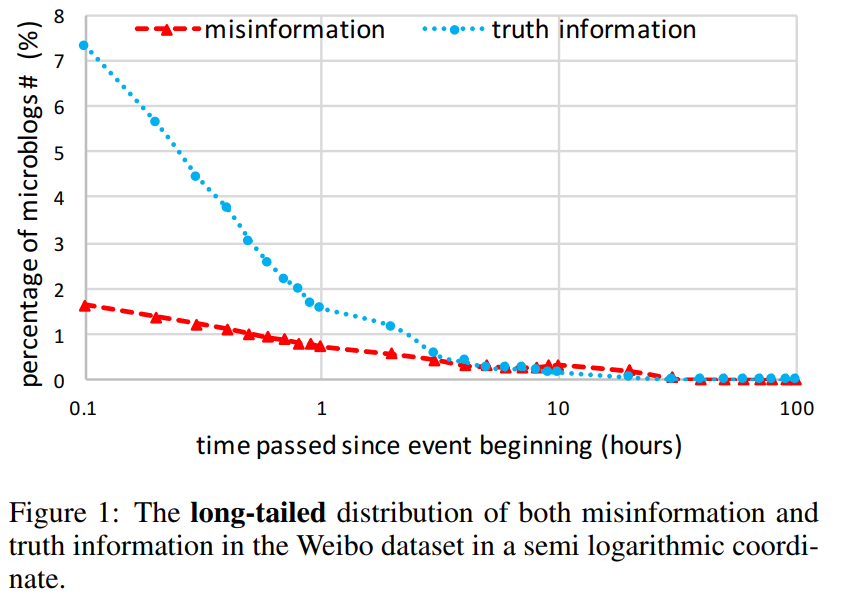
在Twitter数据集中错误信息和真实信息的事件数分别为498和494,在微博数据集中为2313和2351。微博数据集的分布如下。
Proposed CAMI Model
- Problem Definition:给定一组事件,每个事件包含一系列相关的微博帖子,每个微博帖子都有对应时间戳。这里的任务是在事件级别识别事件是否为误报,即通过分析事件的相关微博帖子序列来检测事件是否为误报。
Proposed Model
所提议的CAMI模型的框架如图所示,一共有3个小模块,以下将自底向上描述各模块。
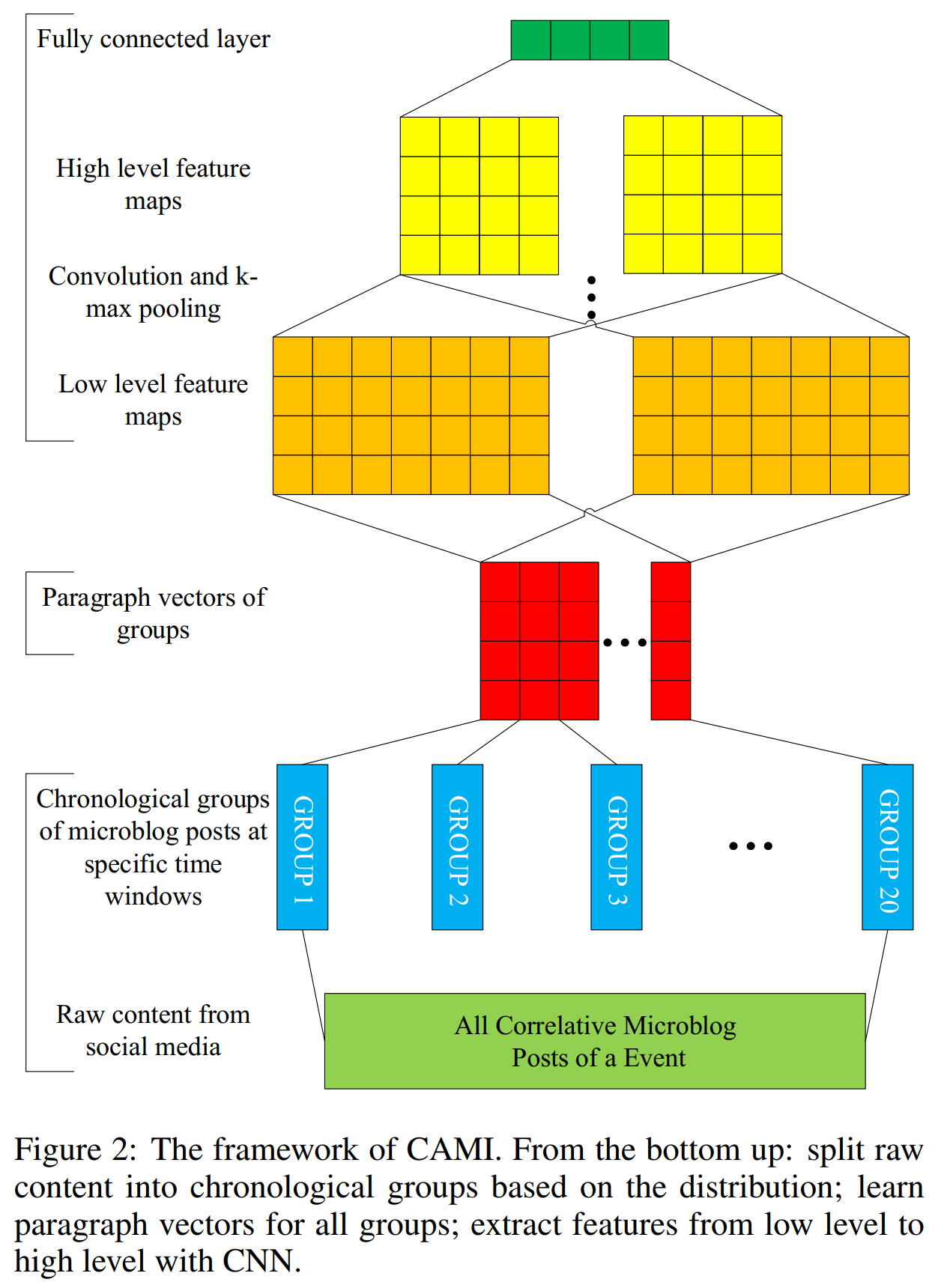
由于虚假信息可能是用一种实话实说的方式来描述的,所以很难从一个特定的微博帖子中识别出虚假信息。相对而言,从一个事件的相关微博帖子序列中检测虚假信息是合理的,虚假信息和真实信息的属性对虚假信息的识别起着至关重要的作用,我们需要将事件的所有微博帖子作为一个整体来处理。
Splitting all correlative microblog posts of an event into several groups:通过对微博帖子建模,将一个事件中所有相关的微博帖子集中到一个时间窗序列中以提取整体特征。首先,一个事件平均由数千条相关微博组成,事件之间存在差异。此外,在某些特定的时间窗口内的微博帖子具有很强的相关性,我们可以将这些相邻的微博帖子作为一个组以代表一个特定的事件阶段。
所有事件都需要以统一的方式进行分割,这样才能提取出有区别的特征。例如,真实信息往往在一开始就被发布或转载,很快就会消失,而错误信息往往在中间阶段吸引了相对持久的注意力。所以不同的微博帖子在同一时间窗口的信息量可能会有所不同。我们需要尽可能确保事件的一个阶段不被间断,也就是说,那些最相关的微博帖子应属于事件阶段的同一个组中。
考虑到所采用的数据集的长尾分布,采用等时间间隔可能会导致各组微博数量不平衡而影响特征学习的效果。最好按时间顺序将所有事件的微博帖子分成等量的组,具体来说,我们收集事件所有相关微博帖子的时间戳,并从每个事件的所有时间戳中减去相应事件的开始时间戳,然后这些时间戳被归一化。最后,整个时间戳按时间顺序平均分成20份,每个时间窗口为
其中$t_i$是第$i$个时间段的结束时间戳,注意可能存在时间窗口使得该窗口内没有微博。
Learning representation for each group via paragraph vector:我们将一个时间窗口的微博帖子作为一个事件段,用一系列的事件段对整体特征进行建模。为了方便起见,这里使用段落向量[Le and Mikolov, 2014]。一个事件内微博帖子的可以看作是一个段落来学习段落表示$\text g_i$,
通过softmax进行预测,
给定一个有$N$个单词的段落,一个单词用在$\mathbf{W}$中的列向量$\mathbf{w}_n$来表示,段落用在$\mathbf{D}$中的列向量$\text{g}_j$来表示,而且$θ$是softmax参数,$h$是拼接或平均运算。上下文单词和段落记忆用于预测当前单词。
Modeling high-level interactions by CNN:CNN常用的架构包括卷积层、$k$-max池化层和全连接层。对于一个$n$阶段的事件实例$e_i$,每个阶段采用$\text{g}_j\in\mathbb{R}^d$做嵌入。我们可以得到实例矩阵$\mathbf{G}\in \mathbb{R}^{d\times n}$,在卷积神经网络,卷积层是通过权重矩阵$\mathbf{C}\in\mathbb{R}^{d\times\omega}$的卷积运算得到的,对卷积结果应用非线性函数,得到特征映射的一个元素为:
其中$\mathbf{G}[:, i: i+\omega-1]$表示$\mathbf{G}$的第$i$到$i+w-1$行,$F$表示Frobenius inner product。最后,我们采用$k$-max池化特性映射$\mathbf{f}$捕捉最重要的特性$f_{max}^k$。
此外,可以重复上面的卷积和池化操作。最后通过softmax获得最终输出$p_{e_i}$。其中$p_{e_i}$为预测事件$e_i$是否属于误报的概率。
Experiments
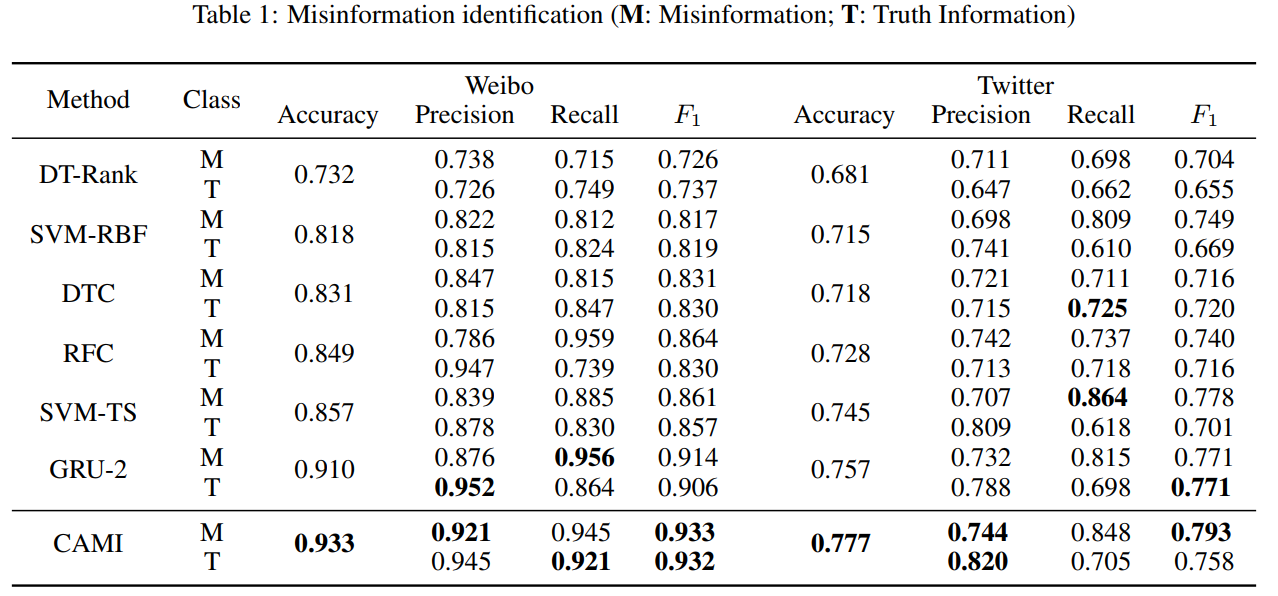
实验相关设置见原论文,结果如下,
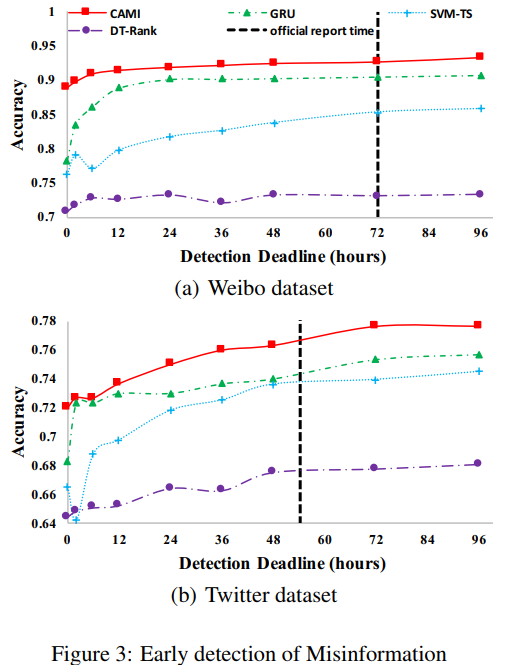
关于早期检测的结果如下。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!