《Modeling Transferable Topics for Cross-Target Stance Detection》笔记
Modeling Transferable Topics for Cross-Target Stance Detection
INTRODUCTION
定向的立场检测方法主要在目标内进行,即使用同一目标的数据对模型进行训练和测试。当我们面对一个新的目标时,我们已经标记了与现有目标有关的数据,但是很少或没有用于新目标的已标记数据。因此,缺乏新目标的标记训练数据限制了特定目标模型的构建。
本课题推动了交叉目标立场检测的研究,利用相关的源目标标记数据来构建新目标模型,先前的两个研究已经解决了跨目标立场检测问题。Augenstein等人整合了目标的语义表示来学习文本表示,Xu等人的进一步利用自注意力机制来关注重点词。然而,他们在训练过程中不考虑任何来自最终目标的信息,因此模型更多地学习到源目标的基于目标特征。此外,他们只利用最终目标来学习文本表示,并没有明确地建立两个目标之间可迁移知识的模型,因此跨目标适应能力相当有限。
跨目标立场检测任务的关键研究挑战是对可转移知识的有效建模,以促进跨目标的适应。用户经常讨论目标的一些从属话题,通过对这些话题的表达可以推断出他们对目标的立场。此外,两个目标之间的共同主题可以作为可转移的知识来利用,以帮助模型实现跨目标。表1为一个示例。虽然两个文本属于不同的对象,但它们都表达了对主题的态度。论文将这些主题知识整合到立场检测模型中,以提高其跨目标适应能力。
论文提出了一种跨目标立场检测方法,将主题知识获取和文本表示学习整合到一个统一的端到端框架中。为了有效获取可转移的主题知识并通过反向传播进行训练,论文采用神经变分推理,利用源目标和最终目标的未标记数据产生潜在的主题,并利用获得的主题知识增强文本表示。论文的工作贡献如下:
- 利用可转移的主题知识进行跨目标的模型适应,并提出了一种有效的跨目标立场检测方法。
- 我们的方法利用来自源目标和最终目标的数据获取主题知识,并在端到端框架中学习表示。
- 实验结果表明,该方法在跨目标立场检测方面优于目前最先进的方法。
PROBLEM STATEMENT
- 源目标一组已标记的文本数据集$\mathcal{D}_s^l=\{(x_s^{(i)},y_s^{(i)})\}_{i=1}^{N_s}$,其中$x_s$是一个句子,$y_s$是立场标签。最终目标的一组未标记的文本数据集$\mathcal{D}_d=\{x_d^{(i)}\}_{i=1}^{N_d}$,还拥有来自两个目标的大量未标记文本(称为外部数据)$\mathcal{D}_e=\{x_e^{(i)}\}_{i=1}^{N_e}$。其中$x_e$属于源目标或最终目标。通常,$N_e\gg N_s\approx N_d$。跨目标立场检测任务是预测$\mathcal{D}_d$中文本的立场标签。
PROPOSED METHOD
论文提出了Variational Transfer Network(VTN)结构用于跨目标立场检测。如图1,它由两个部分组成。第一部分是主题知识获取模块,其目的是利用来自两个目标的大量未标记数据$\mathcal{D}_e$来获取可转移的主题知识。第二部分是一个带有识别器的主题增强记忆网络,它将主题知识存储在记忆中,并使用$\mathcal{D}_s^l$和$\mathcal{D}_d$来学习目标不变表示$h’$与进行立场预测。
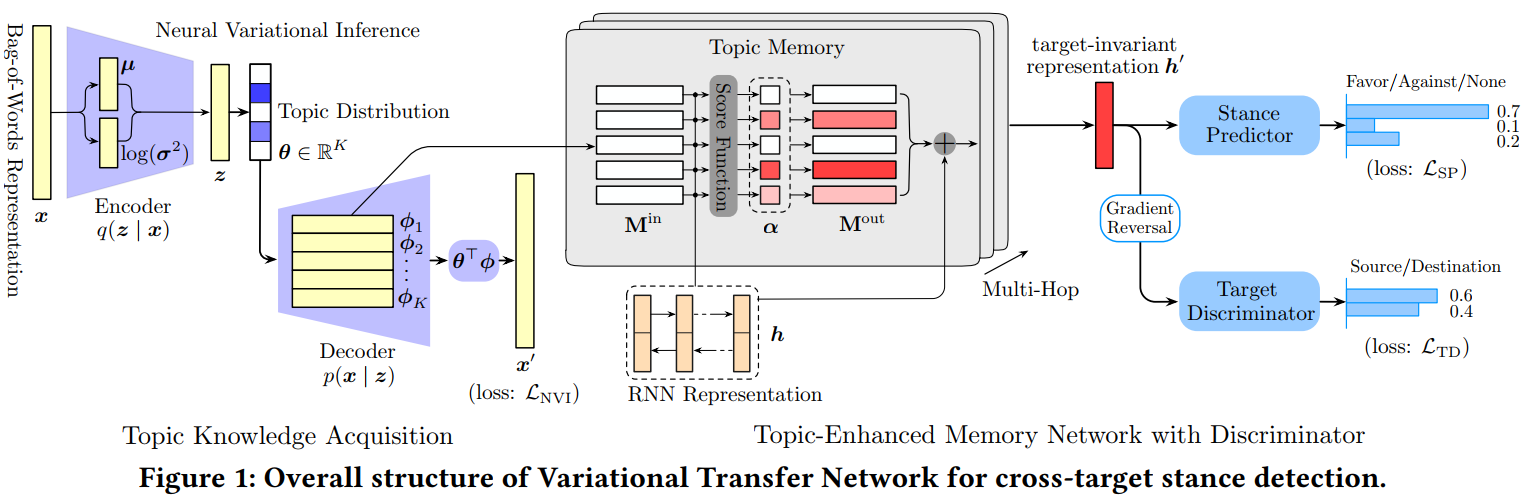
Topic Knowledge Acquisition with Neural Variational Inference
获取可转移的知识是该方法的核心功能,论文采用主题建模方式产生潜在的主题来获取知识,以实现有效的跨目标适应。
Topic modeling based on variational autoencoder:用$K$表示主题建模过程中主题的数量。对于每个主题$k \ (k = 1,2,…,K)$,引入一个待学习的参数向量作为主题嵌入$t_k∈\mathbb{R}^d$,主题知识$T$由这些主题嵌入$T = \{t_1,t_2,…, t_K\}$,给定词嵌入矩阵$E∈\mathbb{R}^{V ×d}$,其中$V$为词汇数量,可以通过计算主题与词的语义相似度,得到每个主题$k$的词分布$ϕ_k∈\mathbb{R}^V$:
在我们的框架中,为了通过反向传播训练主题建模过程,我们采用了neural variational inference,通过变分自编码器(VAE)实现了LDA风格的主题建模。
设$\boldsymbol{x}∈\mathbb{Z}^{V}_+$表示文本$x∈D_e$的词袋表示。基于VAE,每个长度为$N$个单词的文本$x$的生成过程为:
根据先验分布(standard Gaussian)确定一个潜在变量$z∈\mathbb{R}^K$:$z∼N(0, 1)$
得到主题分布$θ = Softmax(\mathbf{W}z)∈\mathbb{R}^K$,其中$W$是一个可学习的矩阵。
对于位置$n(n = 1,2,…, N)$的每个单词,得到$w_n∼\boldsymbol{\phi}^⊤θ$。
这里,得到单词$w_n$的概率是由以下公式计算:
因此我们有$w_n∼\boldsymbol{\phi}^⊤θ$,且$\boldsymbol{\phi}^⊤θ\in\mathbb{R}^V$。
由于$z$的后验推断是难以处理的,VAE引入一个变分分布$q(z\ |\ \boldsymbol{x})$来近似真实的后验。$q(z\ |\ \boldsymbol{x})$是一个对角线高斯函数:$q(z\ |\ \boldsymbol{x}) = N(z;\mu,σ^2I)$,$\mu,σ^2$由多层感知器(MLP)参数化:$\mu= MLP_\mu(\boldsymbol{x}), log(σ^2) = MLP_σ (\boldsymbol{x})$。
objective function:在训练过程中,基于VAE的主题模型以最大化变分下界为目标:
第一项是重建输入$\boldsymbol{x}$,第二项KL散度项作为正则化项,将变后验与先验相匹配。因此,NVI网络的目标函数为:T
Knowledge Transfer with Topic Memory
为了充分利用该网络实现目标间的知识转移,论文将主题知识存储在外部记忆中,并采用多跳记忆网络学习文本表示和预测立场。
Building topic memory:传统记忆网络包含一个输入记忆$M_{in}$和一个输出记忆$M_{out}$。论文采用了简化版本,在网络中只包含一个内存矩阵$M$,即$M = M_{in} = M_{out}$。使用$T$初始化外部记忆,即$M = T$,并在训练过程中进一步更新记忆。
Topic-enhanced text representation learning:形式上,主题内存$M$有$K$个槽$\{m_1,m_2,…,m_K\}$,每个槽位$m_k$保存着对应主题$k$的信息。
从$\mathcal{D}_s^l$选择一个句子,使用一个双向LSTM对其进行编码,选择最后一个时间的两个方向上的隐状态来获取它的向量表示$h$,然后采用注意力机制获取重要的内存插槽(即主题),生成增强的文本表示$h’$:
其中$α_k$为句子与主题$k$的匹配分数,$h$为访问内存的查询向量。主题记忆产生的输出向量$o$对主题知识进行编码,矩阵$\mathbf{W}_1$和$\mathbf{W}_2$是需要学习的参数。
如果采用单跳存储网络,$h ‘$将是用于预测立场的最终表示。进一步将其扩展为多跳样式,利用前一跳产生的$h ‘$作为后一跳的查询向量。
Stance predictor:采用一个带有softmax函数的MLP作为立场预测器,输出预测的立场分布$\hat{y}= softmax (MlP_{SP}(h’))$。通过最小化源目标数据$D_sl$上的交叉熵损失来训练内存网络:
Target-Invariant Representation Learning with Target Discriminator
为了进一步使文本表示更具target-invariant,便于跨目标的模型适应,引入了一个目标识别器来对输入文本的目标标签进行分类,即判断文本属于源目标还是最终目标,实现方法为MLP(记为$MLP_{TD}$)。如果识别器不能预测文本的目标标签,那么它的表示是target-invariant的。引入目标识别器的另一个好处是,可以利用目标目标中的未标记数据来训练主题记忆。
具体来说,给定一个来自$\mathcal{D}_s^l$或$\mathcal{D}_d$的句子,其表示$h ‘$的目的是混淆目标分类器,使目标分类在$\mathcal{D}_s^l∪\mathcal{D}_d$上的交叉熵损失$\mathcal{L}_{TD}$最大化,而分类器本身的目的是使LTD最小化。因此,带有识别器的记忆网络的训练过程是一个对抗性的训练过程,具有如下的极大极小博弈
其中$λ$为权衡参数。我们通过反向传播中的梯度反转操作来实现这个过程,这是一种在基于迁移学习模型中广泛使用的技术。
Optimization
- 采用端到端的培训方式来优化VTN。它由两部分组成:NVI网络训练以及使用$\mathcal{D}_s^l∪\mathcal{D}_d$训练的带有识别器的记忆网络(MN-D)。具体来说,我们迭代训练两部分:首先训练两个epoch的NVI,并使用训练的主题嵌入初始化记忆的MN-D,进一步训练两个epoch的MN-D。然后利用MN-D训练的主题记忆更新主题嵌入,再训练两个epoch的NVI。上述过程迭代直到收敛。?
EXPERIMENTS
实验相关设置见原论文,结果如下
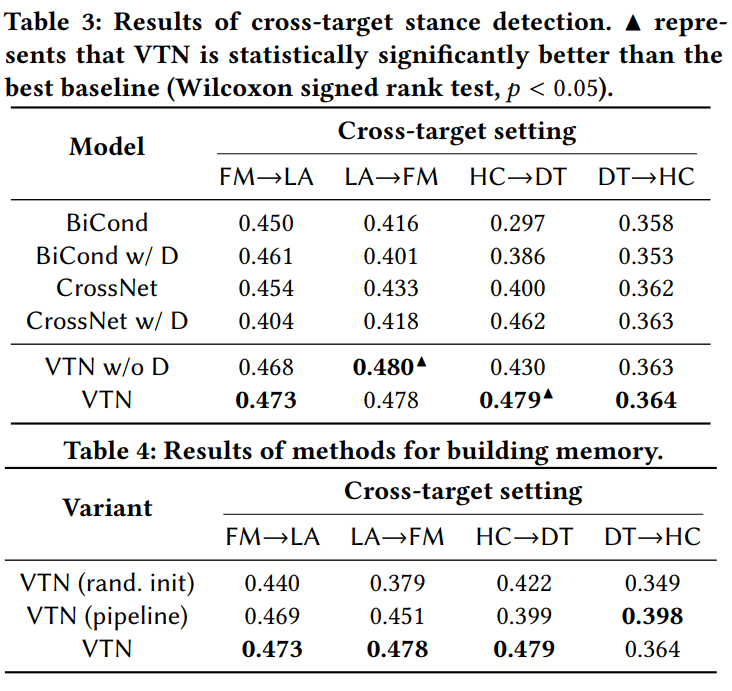
总结
- 查看这篇的论文的原因是基于我们的微博数据集缺少立场标签,若采用其他有立场标签数据所构建的立场分类器对我们的微博数据集进行立场检测,需要考虑立场分类器的跨目标学习能力,即立场分类器是否仍然适用于新任务。与情感分类不同,不同的立场分类在面对不同目标时侧重点不同,而在谣言检测中,目标是起源推文(微博),谣言之间的目标往往不具有相关性。
- 论文通过挖掘不同目标文本内相同的主题存在的联系以实现立场分类任务的跨目标学习,但该方法要求源目标与最终目标存在相关性,如文中实验中的Feminist Movement (FM)与Legalization of Abortion (LA), Hillary Clinton(HC)与Donald Trump(DT)。可以看到这两个实验具有比较高的相关性,这是我们在weibo或推特数据集上没有的,因此该迁移方法并不是简单适用于我们的立场检测。
- 论文提供了使用主题模型指导立场检测任务的思路,而且采用的对抗性训练过程使分类器表现出了target-invariant,这是我们的立场检测所需要的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!